
A – Architecture visée
L’architecture mise en place vise à garantir la haute disponibilité, la sécurité physique des données ainsi qu’un Plan de Reprise d’Activité (PRA) fonctionnel en cas de défaillance majeure.
Elle repose sur les éléments suivants :
- Deux datacenters géographiquement séparés de plusieurs kilomètres
- Données synchronisées en temps réel entre les deux sites
- Un troisième datacenter dédié aux sauvegardes
- Deux serveurs actifs assurant la production
- Un serveur de sauvegarde indépendant
L’objectif est d’obtenir un RPO = 0, c’est-à-dire aucune perte de données, même en cas de panne complète d’un site.
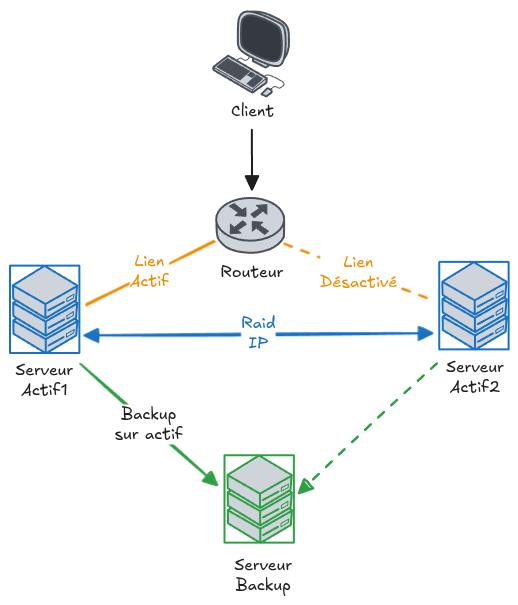
L’architecture logique comprend :
- un client
- un routeur
- deux serveurs actifs (Actif1 et Actif2)
- un serveur de backup
- un lien actif et un lien désactivé
- une synchronisation de type RAID sur IP
B – Prérequis
Machines
Pour la mise en place de cette architecture, les prérequis matériels sont les suivants :
- Deux machines de production
- Un serveur Apache sera installé à des fins d’exemple
- Une troisième machine dédiée aux sauvegardes
Réseau
- Les trois machines doivent pouvoir communiquer sur un réseau interne privé
- Les deux machines actives doivent également communiquer sur un second réseau (NAT)
- Toutes les adresses IP doivent être fixes
Cette configuration permet :
- la synchronisation inter-sites
- la haute disponibilité
- la mise en place d’un PRA robuste
C – Mise en place
1 – Stockage
Avant toute configuration logicielle, un stockage dédié est attaché à chaque machine.
Ce stockage correspondra aux données à synchroniser et à sauvegarder.
- Stockage machine Actif1
- Stockage machine Actif2
- Stockage machine Backup
Les stockages ne doivent pas être montés immédiatement.
a – Création des partitions
Une fois les stockages attachés :
- Vérifier les volumes disponibles :
lsblk
Dans cet exemple, le volume vdb est disponible.
- Partitionner le disque avec
fdisk:
fdisk /dev/vdb
Options utilisées :
n: créer une nouvelle partitionp: partition primaireEntrée: conserver les valeurs par défautw: enregistrer et quitter
Note: Il n’est pas nécessaire de créer un système de fichiers à ce stade.
En cas de problème, la commande suivante permet d’effacer la partition :
dd if=/dev/zero of=/dev/vdb1 bs=1M count=10
2 – RAID sur IP
a – Installation de DRBD
DRBD (Distributed Replicated Block Device) permet la synchronisation des blocs de données entre les machines actives, ainsi que vers la machine de backup.
Installation du paquet :
apt update && apt install -y drbd-utils
Activation du module :
modprobe drbd
Note: La commande suivante permet de vérifier le bon chargement du module :
modinfo drbd
b – Configuration de DRBD
Le fichier de configuration principal est situé dans :
/etc/drbd.d/r0.res
Il doit être identique sur les trois machines.
resource r0 {
on savalaible1 {
device /dev/drbd0;
disk /dev/vdb1;
address 192.168.130.130:7789;
meta-disk internal;
}
on savalaible2 {
device /dev/drbd0;
disk /dev/vdb1;
address 192.168.130.133:7789;
meta-disk internal;
}
on savbackup {
device /dev/drbd0;
disk /dev/vdb1;
address 192.168.130.192:7789;
meta-disk internal;
}
}
Note: Il est impératif que les noms d’hôtes correspondent exactement à ceux du système, sans quoi la configuration ne sera pas reconnue.
Initialisation de DRBD sur les trois machines :
drbdadm create-md r0
drbdadm up r0
Définition du nœud primaire (une seule machine active) :
drbdadm -- --overwrite-data-of-peer primary r0
Création du système de fichiers :
mkfs.ext4 /dev/drbd0
Note: L’état de synchronisation peut être vérifié avec :
cat /proc/drbd
drbdadm status
c – Démarrage et automatisation
La phase d’initialisation de DRBD nécessite une intervention manuelle.
Une automatisation complète n’est pas viable sans gestion de cluster.
3 – Basculement automatique avec Heartbeat
Info: Heartbeat est aujourd’hui considéré comme obsolète** et remplacé par des solutions plus modernes (Pacemaker, Corosync).
Cependant, il est volontairement utilisé dans cet article à des fins pédagogiques, pour illustrer simplement les mécanismes de basculement automatique et de haute disponibilité.
a – Configuration de Heartbeat
Installation :
apt-get install -y heartbeat
Fichiers de configuration dans /etc/ha.d/ :
ha.cf: configuration généraleharesources: ressources géréesauthkeys: clé d’authentification partagée
Permissions :
chmod 600 /etc/ha.d/authkeys
ha.cf
mcast enp1s0 239.0.0.1 694 1 0
warntime 4
deadtime 5
initdead 15
keepalive 2
auto_failback off
node savalaible1
node savalaible2
haresources
savalaible2 IPaddr::192.168.110.158/24/enp1s0 drbddisk::r0 \
Filesystem::/dev/drbd0::/mnt::ext4
authkeys
auth 3
3 md5 cle-secrete
Démarrage :
/etc/init.d/heartbeat start
Après quelques secondes, le volume est automatiquement monté sur le nœud actif.
b – Erreur lors du redémarrage des services DRBD
Il peut arriver que, lorsque les deux machines actives sont arrêtées simultanément, une erreur apparaisse au redémarrage du service DRBD :
Split-Brain detected but unresolved, dropping connection!
Cette situation correspond à un split-brain, c’est-à-dire une divergence des données entre les nœuds.
Procédure de résolution
Étape 1 :
Définir un nœud comme secondaire et rejeter ses données :
drbdadm secondary all
drbdadm disconnect all
drbdadm --discard-my-data connect all
Étape 2 :
Définir l’autre nœud comme primaire et reconnecter :
drbdadm primary all
drbdadm disconnect all
drbdadm connect all
La commande suivante doit désormais indiquer que les deux nœuds sont connectés :
drbdadm status
4 – Mise en place des services
Nous allons maintenant installer un serveur LAMP sur les deux machines actives.
Installation des paquets
Sur les deux nodes :
apt install -y apache2 php insserv libapache2-mod-php php-cli \
php-common php-curl php-gd php-json php-mbstring php-xml \
php-xmlrpc php-soap php-intl php-zip
Gestion du démarrage d’Apache
Le démarrage automatique d’Apache doit être désactivé, car c’est Heartbeat qui gérera le lancement et l’arrêt du service.
Sur les deux nodes :
insserv -r apache2
/etc/init.d/apache2 stop
Mise en place du répertoire web partagé
Sur le nœud primaire, création du répertoire :
mkdir -p /mnt/www/html
Création d’une page de test :
<?php
echo "Node ".gethostname()."\n";
?>
Redirection du répertoire Apache
Le répertoire par défaut /var/www est remplacé par un lien symbolique vers le volume DRBD :
Sur les deux nodes :
rm -rvf /var/www/
ln -s /mnt/www/ /var/
Note: Vérification possible avec :
ls -la /var/www
Intégration d’Apache dans Heartbeat
Installer rsync :
sudo apt install rsync
Modifier le fichier haresources (exemple pour la node 1) :
savalaible2 IPaddr::192.168.110.158/24/enp1s0 drbddisk::r0 \
Filesystem::/dev/drbd0::/mnt::ext4 apache2
Redémarrage des services :
systemctl restart apache2
/etc/init.d/heartbeat reload
Note: Lors de l’accès au site via un navigateur, le nom du serveur affiché permet de vérifier quel nœud est actif. En arrêtant la node principale, la seconde prend automatiquement le relais.
Attention: Tout module PHP ou Apache ajouté doit impérativement être installé sur les deux nodes.
5 – Sauvegarde des services
La sauvegarde est réalisée depuis la machine de backup, à l’aide de rsync et cron.
Préparation
Connexion du serveur de backup en tant que nœud secondaire :
drbdadm connect r0
Installation de rsync sur les trois machines :
sudo apt install rsync
a – Configuration de l’accès SSH
Sur le serveur de backup :
Génération d’une clé SSH sans mot de passe :
ssh-keygen -t ed25519 -b 4096
Copie de la clé publique vers les deux machines actives :
ssh-copy-id root@192.168.130.130
ssh-copy-id root@192.168.130.133
Note: Le répertoire
/mntdoit être accessible en lecture depuis le serveur de backup.
b – Préparation du répertoire de sauvegarde
Sur le serveur de backup :
mkdir -p /backup/
c – Script de sauvegarde
Création du script :
nano /opt/backup_script.sh
Contenu du script :
#!/bin/bash
SERVER1="192.168.130.130"
SERVER2="192.168.130.133"
BACKUP_DIR="/backup"
REMOTE_MOUNT_POINT="/mnt"
RSYNC_OPTIONS="-avz --delete -e"
check_mount() {
SERVER_IP=$1
ssh -o BatchMode=yes -q $SERVER_IP "mount | grep -q $REMOTE_MOUNT_POINT" \
&& echo "mounted" || echo "not_mounted"
}
echo "Checking server: $SERVER1"
if [ "$(check_mount $SERVER1)" "mounted" ]; then
rsync $RSYNC_OPTIONS ssh $SERVER1:$REMOTE_MOUNT_POINT/ $BACKUP_DIR/
exit 0
fi
echo "Checking server: $SERVER2"
if [ "$(check_mount $SERVER2)" "mounted" ]; then
rsync $RSYNC_OPTIONS ssh $SERVER2:$REMOTE_MOUNT_POINT/ $BACKUP_DIR/
exit 0
fi
echo "Error: /mnt is not mounted on either server"
exit 1
Rendre le script exécutable :
chmod +x /opt/backup_script.sh
d – Automatisation avec Cron
Édition de la crontab :
crontab -e
Exécution toutes les heures :
0 * * * * /opt/backup_script.sh
Note: L’état du service cron peut être vérifié avec :
systemctl status cron
e – Sécurisation SSH
Restriction de la clé SSH dans authorized_keys sur les machines actives :
command="rsync --server -logDtpr . /mnt/" ssh-rsa AAAA...
Cette restriction empêche toute autre commande SSH via cette clé.